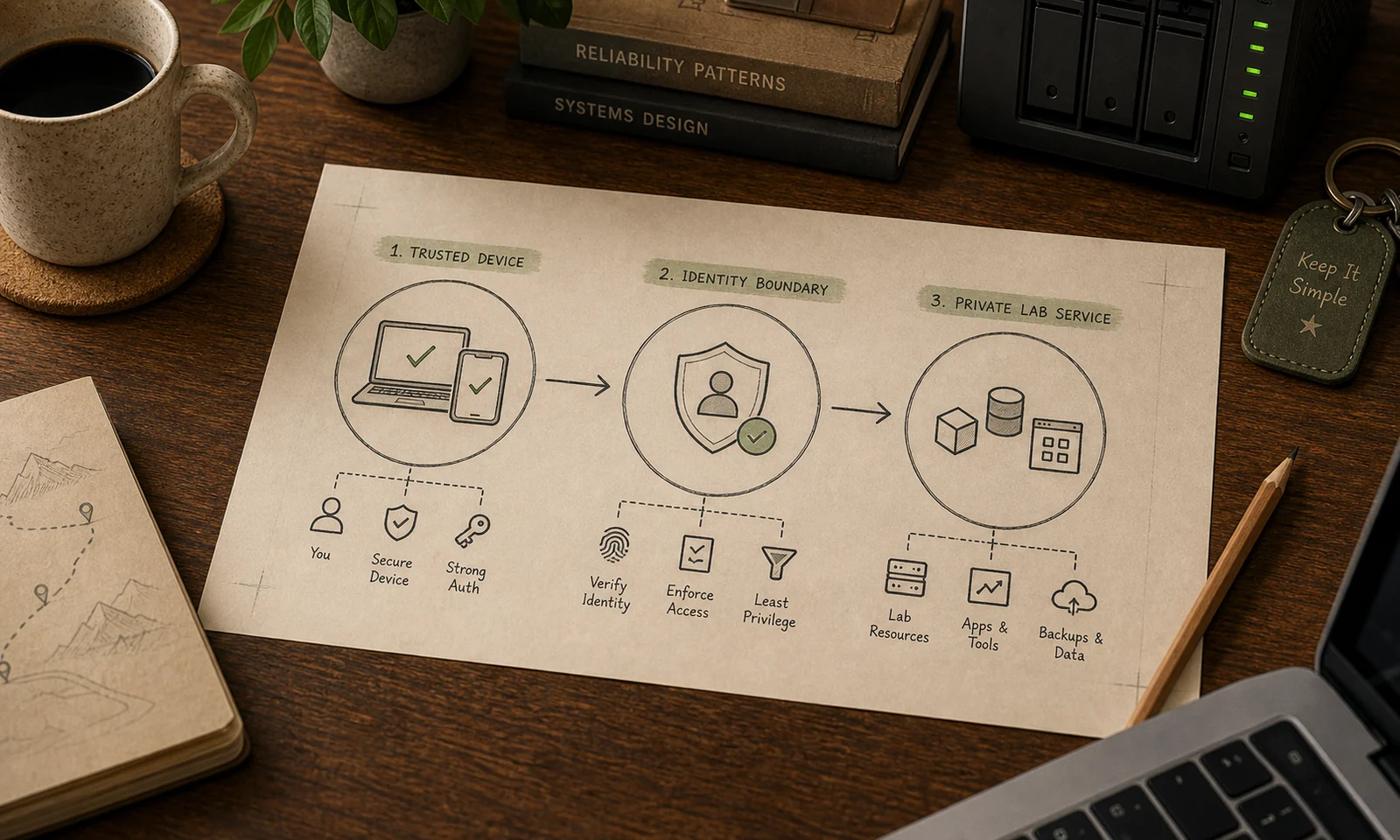
Remote access was one of the first places where the homelab started feeling less like a pile of services and more like an actual system.
The goal was not exotic: I wanted to reach my own services, computers, smart home tools, and AI-agent environments when I was away from home. The constraint mattered more than the goal: I did not want to poke random holes in the firewall just to make that convenient.
As the lab grew into a small constellation of Proxmox, Synology, Home Assistant, media services, DNS filtering, Linux VMs, browser tools, and AI-agent experiments, “can I reach it?” became the wrong question.
The better question became: “what is the least public access path that still makes this usable?”
So the access model became three lanes:
Trusted personal device -> private overlay network -> lab services
Browser-only session -> identity-protected tunnel -> selected web interfaces
Browser-only session -> protected desktop gateway -> internal desktop targetsThat split has worked well. Tailscale is the normal path for devices I own and trust. Cloudflare Tunnel is the fallback for situations where installing Tailscale is not practical, especially when I only need browser access. Guacamole is the remote desktop layer when I need a GUI through that browser-only path.
The Starting Problem
At first, remote access sounds like a simple VPN decision. Pick a tool, connect back home, and call it done.
In practice, I had a few different requirements:
- Managing Home Assistant when I am away.
- Reaching NAS and camera interfaces without exposing them publicly.
- Using Guacamole for browser-based remote desktop access.
- Connecting to AI-agent VMs and work/playground systems.
- Keeping DNS filtering available through AdGuard even off-network.
- Reaching internal tools from devices where I cannot install extra software.
- Keeping Proxmox, Synology, SSH, RDP, VNC, and admin dashboards away from direct public exposure.
- Making the system understandable months later, not just functional today.
Those are not all the same risk. A laptop I control, authenticated into a private overlay network, is different from a browser session on a constrained machine. The access design needed to reflect that.
The Three-Lane Model
The cleanest mental model is three access lanes:
| Use case | Best path | Why |
|---|---|---|
| SSH to a Linux VM | Tailscale | Private, direct, and tied to a trusted device. |
| Proxmox or Synology administration | Tailscale | Management surfaces should stay private. |
| Home Assistant from personal devices | Tailscale | It is part of the trusted daily workflow. |
| Browser-only web app | Cloudflare Tunnel + identity access | No client install needed, but still gated. |
| Remote desktop from a browser | Guacamole behind an access layer | Useful when native clients are unavailable. |
| Public portfolio website | Static hosting | Public content belongs on public infrastructure, not inside the lab. |
The important part is that these tools are not competing with each other. They are different doors for different trust levels.
Default Path: Tailscale
Tailscale became the default because it made remote access feel boring in the right way.
My trusted personal devices, computers, VMs, and management systems can join the private overlay network. From there, I can reach important services without publishing them directly to the internet.
The features that became most useful were:
- MagicDNS for private naming.
- Tailscale SSH for administration.
- Exit nodes for selected workflows.
- Private service routing for browser-friendly access to internal apps.
- Manual approval for new devices.
- Infrastructure devices with key expiry disabled when surprise reauthentication would be painful.
I do not currently use subnet routing as the main pattern. Most access is either direct device membership or private service routing.
The biggest mindset shift was to stop thinking in port forwards. Instead of asking which port to expose, I try to ask which access path fits the service.
Private Service Routing
One of the most useful patterns has been routing private overlay names to containerized services.
Instead of installing Tailscale into every container, a small always-on routing layer can point private names at internal web apps. That supports things like Git hosting, Guacamole, Homepage, Portainer, Uptime Kuma, automation tools, and AI-related interfaces without making those services public.
That setup is convenient, but it also taught me a lot.
I ran into same-host and hairpin-style routing issues while trying to reach services from inside the same virtualization environment. At one point I isolated a VM onto a separate network segment while troubleshooting. The final fix was less about memorizing a product feature and more about understanding how private service routing, Linux route advertisement, NAT behavior, and DNS resolution interact.
One version of the problem was especially educational: a private name could resolve correctly while the traffic still failed to route. That was a useful reminder that DNS is only the map. Routing is the road. Both have to agree.
That is exactly the kind of homelab problem I like: annoying in the moment, useful later.
DNS Became Part Of Remote Access
AdGuard also became part of the remote access story.
The local network points at AdGuard for DNS filtering, but remote devices connected through the private overlay can use it too. That means my laptop and phone can keep using the same filtering approach when I am away.
There were some small reliability lessons here:
- DNS latency is very noticeable when it is wrong.
- Cache sizing matters more than I expected.
- Parallel upstream requests improved responsiveness.
- IPv6 DNS behavior can create confusing device-specific problems.
- Blocking telemetry can occasionally break apps in ways that look unrelated to DNS.
The lesson was not just “DNS filtering is nice.” It was that DNS becomes core infrastructure once everything depends on it.
Browser Fallback: Cloudflare Tunnel
Cloudflare Tunnel fills a different role.
I use it when I need browser access from a device where installing Tailscale is not realistic. The tunnel is protected by identity and multi-factor authentication, and it only exposes selected web interfaces.
The most useful example is Guacamole. With Guacamole behind an identity-protected tunnel, I can reach a desktop session through a browser when a native remote access client or private overlay client is not available.
That does not mean every internal service should get browser access. The hard part is deciding what deserves that path at all.
Tunnel access also has a different feel from direct private overlay access. It is convenient and stable once configured, but it can be slower or more sensitive to browser behavior. For one workflow, privacy/incognito settings and browser compatibility created weird errors that were easier to avoid with a dedicated browser profile for that access path.
That became a useful pattern: dedicated profile, dedicated authentication session, fewer extension and privacy-mode surprises.
My current rule of thumb is:
Use Tailscale when I control the device.
Use Cloudflare Tunnel when I only need a browser session.
Avoid open firewall ports for lab services.Guacamole: Useful, Not Fancy
Guacamole is not the prettiest tool in the stack, but it solves a very real problem.
It gives me browser-based remote desktop access to systems I want to reach without installing a client on the machine I am using. It works well for Windows RDP and Linux desktop sessions. It did not work as nicely for macOS VNC, so I stopped trying to force that path.
Guacamole also deserves to be treated as infrastructure, not just another app. It has a web frontend, a proxy service, a database, remote connection targets, its own authentication considerations, and optionally an external identity layer in front of it.
That was a useful reminder: open source tools can be incredibly practical without being polished. The question is not whether the interface is beautiful. The question is whether the tool fits the access model and fails in understandable ways.
AI Access Added Another Layer
The remote access model also matters for AI-agent experiments.
Some agent workflows need access to local machines, web interfaces, model providers, or internal tools. That makes access boundaries more important, not less. I have experimented with private access patterns for AI systems, including proxy-style approaches that avoid dropping long-lived model API keys directly into every environment.
The public version of the lesson is simple: agent access should be treated like infrastructure access. Give it a clear path, keep credentials scoped, and avoid making internal tools public just because an automation needs to reach them.
What Still Needs Work
The setup works, but it is not perfect.
The biggest future improvement is stricter ACL discipline. Right now the system is convenient, and new devices require approval, but the private network could be cleaner if roles and device groups were more explicitly separated.
Other areas I want to improve:
- Better documentation of which services are reachable through which path.
- Cleaner internal naming for devices that cannot run Tailscale.
- More intentional review of old devices and access grants.
- Clearer separation between daily-use access, admin access, and experimental agent access.
- Better notes for tunnel routing so I do not have to rediscover the setup months later.
- Backup access paths for core services when one access layer is down.
What I Learned
Remote access is not one feature. It is a set of trust decisions.
The most useful design choice was splitting access into separate lanes: private overlay access for trusted devices, identity-protected browser access for constrained situations, and a protected desktop gateway when I need GUI access from a browser.
The final design principle is simple:
Keep private things private.
Expose only what needs to be exposed.
Put identity in front of convenience.
Document the weird parts before future-you has to rediscover them.The practical lesson is also the professional one: convenience is part of security. If the safe path is easy enough to use, I am less tempted to create shortcuts I will regret later.