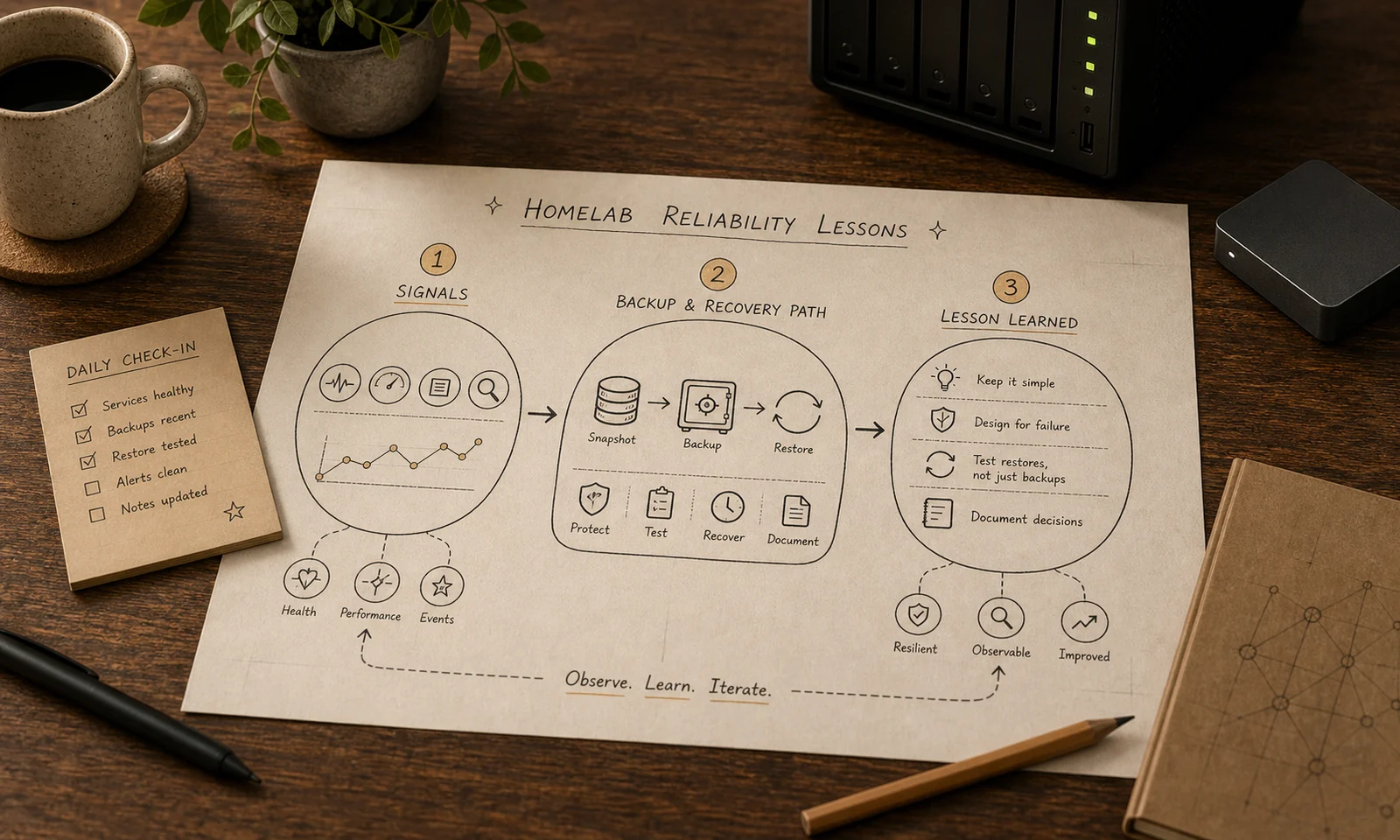
Reliability is not just uptime. In a personal lab, it is the ability to understand what changed, recover from mistakes, and know which services actually matter.
The most important services are usually the least glamorous ones: DNS, remote access, backups, and the home automations people expect to work. If those break, the lab stops feeling like a learning playground and starts feeling like a chore.
That has changed how I think about complexity. It is fine for AI-agent experiments, media workflows, or new automation tools to be complicated while I am learning. It is not fine for DNS, backup access, or daily smart-home controls to be mysterious when something breaks.
Plain Lessons
- RAID or SHR is redundancy, not backup.
- Sync is convenience, not full recovery.
- Snapshots are rollback, not a disaster plan.
- Backups are promises until restores are tested.
- Core services should be more boring than experiments.
- Update review beats blindly chasing every latest tag.
The next reliability improvement is not another dashboard. It is a small restore-test log and a few runbooks for what to do when DNS, remote access, or the main compute host is unavailable.